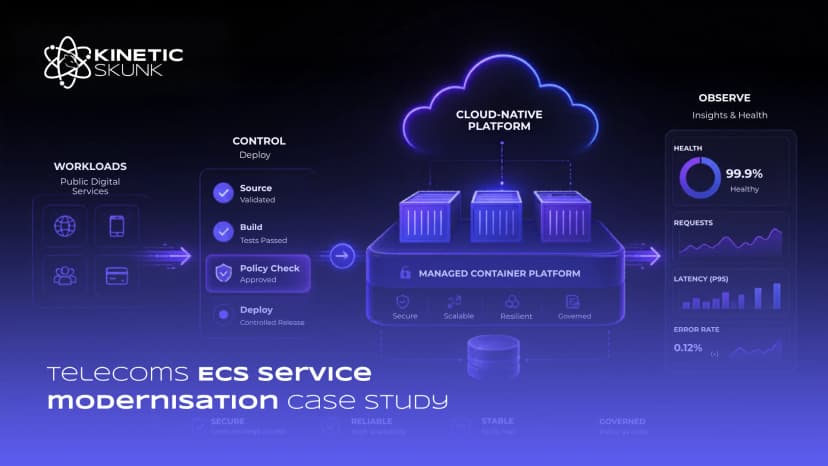
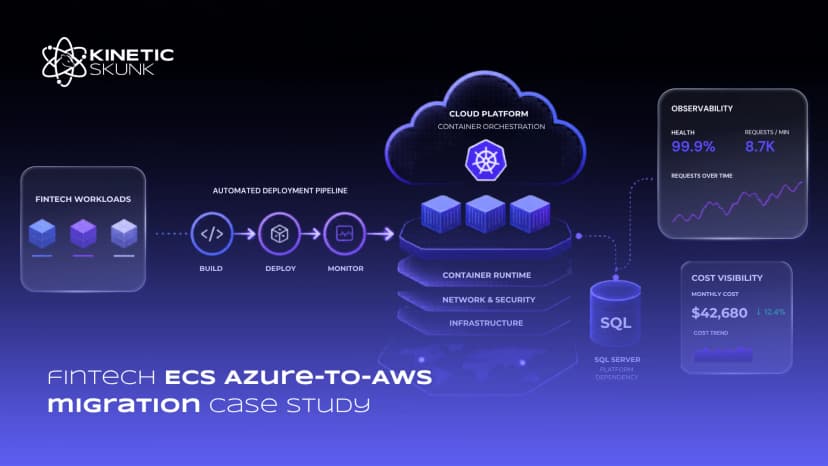
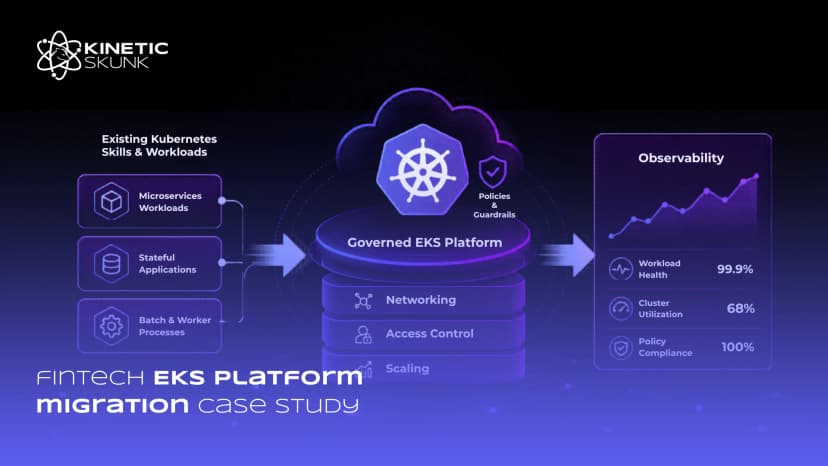
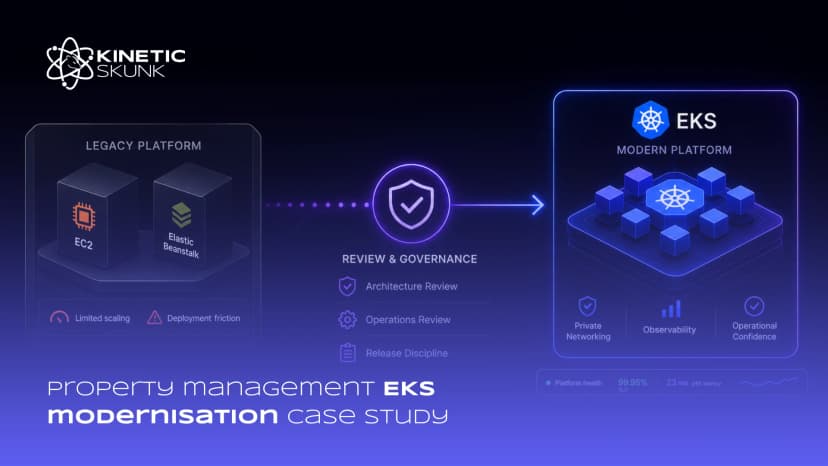
Existing platform
Already running systems? Improve visibility.
We review services, telemetry, logs, traces, metrics, alerts, dashboards, ownership, and investigation paths before changing what teams already rely on.
- 1
Observability estate assessment
Map services, infrastructure, telemetry sources, dashboards, alerts, ownership, and current investigation workflows.
Known visibility surface
- 2
Signal and gap review
Separate useful signals from noise, identify blind spots, and prioritise the telemetry needed for managed operations.
Prioritised visibility plan
- 3
Instrumentation alignment
Align metrics, logs, traces, service naming, tags, and telemetry standards to the way the platform is operated.
Consistent telemetry model
- 4
Dashboard and alert design
Create dashboards and alerts that reflect service impact, operational priority, and realistic response paths.
Actionable operational view
- 5
Managed platform handover
Document monitoring routines, alert ownership, investigation paths, and support expectations for ongoing operations.
Operable observability model